
It started slowly, then happened all at once. AI-generated images went from incoherent, postage stamp sizes to high-quality, photorealistic images in the last couple of years. How did this happen?
Think about how ubiquitously computers interpret your speech these days. Your phone, Alexa, Google Assistant — this tech is everywhere today. It can be fun and often useful, but it doesn’t feel like magic. For it to feel that way, our experience would need to be much more tangible.
“Any sufficiently advanced technology is indistinguishable from magic”
Arthur C. Clarke’s Third Law
I began building a business amid a Cambrian explosion of AI in 2014. Back then, Natural Language Processing (NLP) was one of the most exciting technologies, enabling computers to make sense of human speech and messages. I saw the improvements of these technologies up close via partnerships with companies like IBM (with its famous first mover Watson), Google, and Amazon. Progress was swift, with new platforms, acquisitions, and upgrades announced about every year. By 2018, the tech had matured significantly while becoming 10x cheaper and easier to use.
From Language Understanding To Images
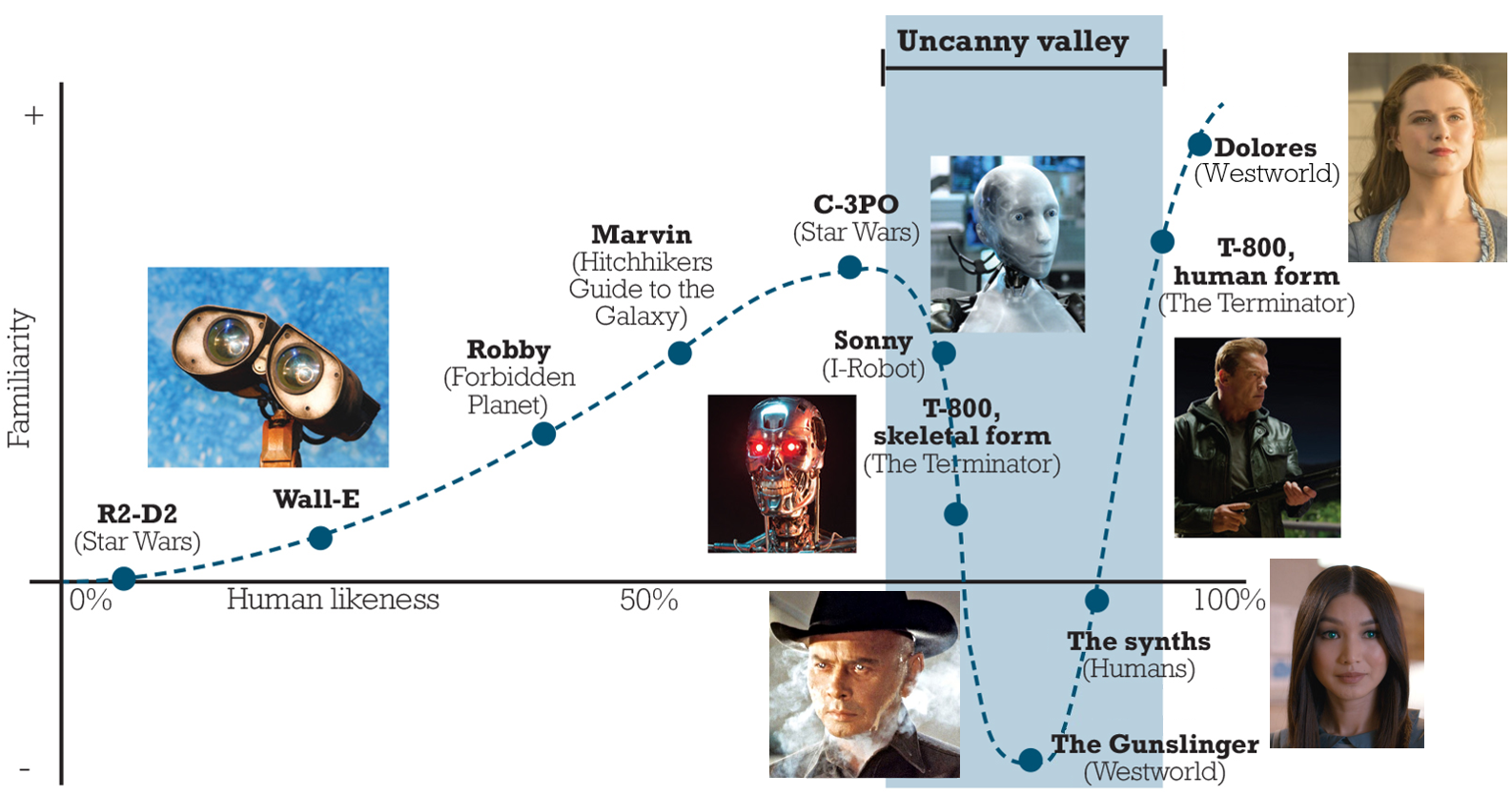
With NLP approaching ‘solved problem’ territory around 2020, researchers focused more on the next frontier: visuals. Generating images is a significantly harder challenge given that more of the human brain seems to be dedicated to processing visual information than auditory. Even when computer graphics get very good, including in big-budget blockbuster movies, our brain can often quickly differentiate what’s real from synthetic images. Images or videos that are nearly photorealistic but not quite there are said to fall into the ‘uncanny valley,’ where they often make viewers uncomfortable.
In the visual medium, the hottest current application of AI is in text-to-image (TTI) systems. Yes, you can now think of anything you want*, type it into a box, and out comes a detailed, high-resolution image in seconds. Let’s see a couple of famous examples (all the input provided to the AI is the text ‘prompt’ below the image):

And now, some examples I created with DALL-E 2:



If your mind isn’t blown yet, check out these examples of inpainting and outpainting respectively, in which the AI removes or adds information to a pre-existing scene:


These examples alone would take human artists hours to do well. AI can now produce them automagically in seconds!
What’s Underappreciated Now
Three significant factors about these developments are, in my opinion, much less widely known than they should be:
- The progress that was once incremental seems to be going vertical. Here’s what year-over-year progress in the most famous TTI AI (OpenAI’s DALL-E) looks like:

- To paraphrase one of my favorite YouTubers (Two Minute Papers), in scientific research, it’s important not to look at where we are today but at where we will likely be 1-2 years down the line based on current trends. And that trend looks at least 10x faster from my vantage point relative to what I saw back in 2014 when innovating in the NLP space.
- In the ~3 months between me discovering, tinkering with, and writing about TTI systems, half a dozen more such systems have come online, including two hugely impressive entrants from Google (Parti and Imagen) that best DALL-E 2 in certain respects (e.g. rendering legible text in generated images).
- This space has become crowded already! TTI innovation is poised to further accelerate with 10+ entrants competing for future market share.
- Arguably most importantly, from a practical and business perspective, the relative cost of creating new images is about to plummet. Not by 10 times, 100 times, or even 1000 times when compared with hiring a graphic designer, photographer, or other creative to carry out your vision. Millions of people will soon have the ability to generate novel images via easy-to-use apps. The cost to generate novel scenes and images will approach zero within 5 years at this rate. Infinite creative output is about to become FREE the way that searching the web, calling your friends, and converting your voice to text suddenly became free in recent years!
The cost to generate novel scenes and images will approach zero within 5 years at this rate.
To recap, an image output that may have cost $50-5000 and taken a week to produce in 2020 will likely cost pennies and be generated in seconds in 2025. What kind of practical image output, you ask? A social media post, specific stock photo, ad for your company, YouTube thumbnail, funny animal photo, meme… literally anything your mind can conjure.
Predictions
TTI is just the beginning. Some interesting consequences of these developments in the coming 2-5 years:
- Differentiating synthetic images from real ones will become critical. Yes, in low-stakes environments like most social media, it may not matter whether your friend’s stunning new cat picture never really happened. However, what about news stories? And online financial account access, where you upload a picture of your ID near your face? Of course, the researchers working on TTI are already considering how best to safeguard the use of this tech. And as issues inevitably arise, so too will the incentives to solve them.
- As a former animator, I immediately began experimenting with generating a series of images with TTI to generate animations. Conveniently, text-to-video (TTV) is another burgeoning area of research, with one TTV tool already freely available for developer use. And it’s also not half bad! Here are example outputs:
- Thinking sequentially from here: once TTI gets good enough for mass use, more advanced AI systems will be able to generate animations, videos, short stories, TV episodes, movies, virtual reality environments, and entire video games where you are the creator. For example, you might one day put on your smart glasses and say:
“Let’s play. Load up a Call of Duty-style game that takes place in a storm on Jupiter’s Great Red Spot where the bad guys are all Storm Troopers and the good guys are Neo and his buddies from the Matrix. We’re all driving DeLoreans and the guns shoot confetti.”
The industries built around providing stock photos, videos, and design as a whole are already on the precipice of major disruption. This will be interesting, fun, and likely profitable to watch closely.
Onwards and upwards.
* Deepfakes, NFTs, and adult content are usually prohibited for obvious reasons.